Technical Report
HetCCL: Accelerating LLM Training with Heterogeneous GPUs
January 30, 2026
Authors: Heehoon Kim, Jaehwan Lee (SNU), Taejeoung Kim (Samsung Research), Jongwon Park (SNU), Jinpyo Kim (SNU), Pyongwon Suh (Samsung Research), Ryan H. Choi (Samsung Research), Sangwoo Lee (Samsung Research), and Jaejin Lee
Abstract
The rapid growth of large language models is driving organizations to expand their GPU clusters, often with GPUs from multiple vendors. However, current deep learning frameworks lack support for collective communication across heterogeneous GPUs, leading to inefficiency and higher costs. We present HetCCL, a collective communication library that unifies vendor-specific backends and enables RDMA-based communication across GPUs without requiring driver modifications. HetCCL introduces two novel mechanisms that enable cross-vendor communication while leveraging optimized vendor libraries, NVIDIA NCCL and AMD RCCL. Evaluations on a multi-vendor GPU cluster show that HetCCL matches NCCL and RCCL performance in homogeneous setups while uniquely scaling in heterogeneous environments, enabling practical, high-performance training with both NVIDIA and AMD GPUs without changes to existing deep learning applications.
1. Introduction
The recent emergence of trillion-scale deep learning (DL) models (Fedus et al., 2022; Achiam et al., 2023; Du et al., 2022) has enabled solutions of previously intractable problems. A key enabler behind this advancement is the high computational capability of heterogeneous cluster systems equipped with various hardware accelerators (e.g., GPUs, NPUs, and FPGAs), which makes it feasible to train and run inference on such massive models. Among these systems, GPU-based platforms play a dominant role in DL, with NVIDIA or AMD GPUs serving as the de facto standard (Otterness and Anderson, 2020; Lehdonvirta et al., 2025).
To enable efficient training and inference of DL models across multiple GPUs, a variety of parallelization techniques have been developed. The most representative approaches are data parallelism (Rajbhandari et al., 2020) and model parallelism, including tensor, pipeline, and expert parallelism (Shoeybi et al., 2019; Huang et al., 2019; Shazeer et al., 2017). Although these techniques differ in how computations and data are distributed across GPUs, modern large-scale training systems rely on parallelization to improve hardware utilization, making efficient coordination across devices increasingly important (Narayanan et al., 2021; Singh et al., 2023).
In multi-GPU parallel training or inference, inter-GPU communication is crucial for sharing computation results and synchronizing model states. Collective communication operations, such as All-Reduce, All-Gather, and Reduce-Scatter, are commonly employed for this purpose. Consequently, most accelerator vendors provide optimized collective communication libraries (CCLs) tailored to their hardware. Examples include NVIDIA NCCL (NVIDIA, 2025b), AMD RCCL (AMD, 2025c), and Intel oneCCL (Intel, 2025).
Training large-scale models typically requires massive GPU-based clusters. In practice, most organizations expand their clusters by acquiring GPU systems in a piecemeal fashion (Park et al., 2020; Ding et al., 2021). This incremental procurement approach allows continued use of existing resources while integrating newer hardware. As a result, the infrastructure becomes heterogeneous, comprising various types of GPUs, sometimes even from different vendors.
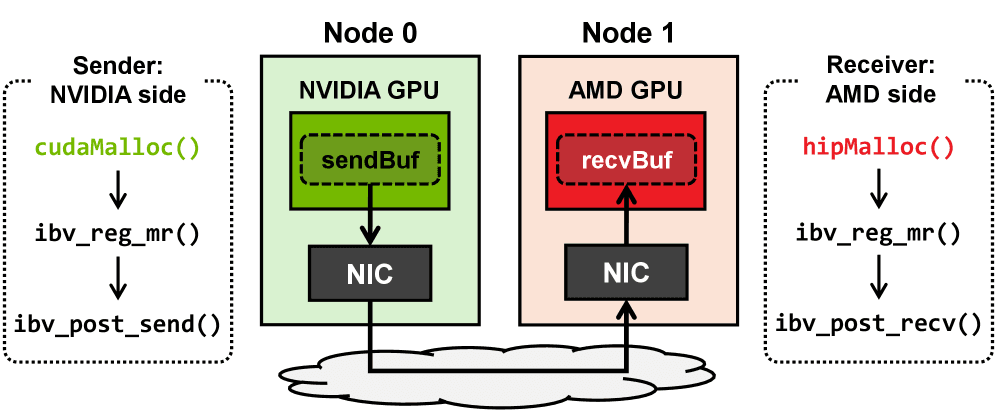
While GPUs from different vendors share similar design philosophies and architectures, they require distinct frameworks and toolchains, making cross-vendor software development challenging. Thanks to ongoing community efforts, full-featured DL frameworks are now available for each vendor’s GPUs. For instance, PyTorch (Paszke et al., 2019) can be configured to support either NVIDIA or AMD GPUs. However, parallel training across GPUs from different vendors remains infeasible because of the incompatibility of their communication backends. DL frameworks depend on vendor-specific libraries, such as NCCL for NVIDIA GPUs and RCCL for AMD GPUs, which are not interoperable.
As DL workloads scale to larger sizes, the ability to achieve fast and reliable communication across heterogeneous GPUs is becoming a crucial factor for building scalable and cost-effective AI infrastructure. Investigating such communication, particularly between NVIDIA and AMD GPUs, is not only timely but also essential for the advancement of the next generation of distributed ML systems. For this purpose, this paper presents HetCCL, a CCL that supports GPUs from multiple vendors. To the best of our knowledge, HetCCL is the first work to enable transparent utilization of all multi-vendor GPUs in a heterogeneous cluster. No source code modifications are required at any level, including the driver, runtime, compiler, and application. In particular, it supports NVIDIA and AMD GPUs, the two leading vendors by market share, which together dominate the accelerator market (approximately 88% and 12%, respectively) (Lehdonvirta et al., 2025). By replacing original communication backends (i.e., NCCL and RCCL) with HetCCL, existing parallel training code written in DL frameworks (e.g., PyTorch) can use both vendors’ GPUs without further modifications.
The key contributions are summarized as follows:
- We propose HetCCL, the first cross-vendor CCL that enables DL model training and inference on heterogeneous clusters with both NVIDIA and AMD GPUs.
- We present a method for direct point-to-point communication (i.e., RDMA) between different vendor GPUs.
- We describe the design and implementation of heterogeneous GPU collective communication operations, with an emphasis on challenges, such as abstracting platform-specific APIs and integrating vendor-optimized operations into a unified framework.
- We evaluate the training performance of large language models in a multi-vendor GPU cluster and demonstrate that it is much faster than homogeneous setups without any straggler effects or model accuracy drops.
We discuss the limitations of this work and outline directions for future research in Appendix A.
Please read the full paper on arXiv.