
December 26, 2025
SLOPE Engine improves long-context prefill performance by applying context parallelism across multiple GPU servers. This also helps efficiently utilize older-generation GPUs.

November 18, 2025
Moreh combine Tenstorrent’s lightweight and scalable hardware with our proprietary software stack to deliver an efficient and flexible solution for large-scale AI data centers.

Moreh and Tenstorrent Unveil Scalable, Cost-Efficient AI Data Center Solution at SuperComputing 2025
November 17, 2025
Moreh, a provider of optimized AI infrastructure software, and Tenstorrent, an AI semiconductor company, are unveiling a scalable, cost-efficient AI data center solution at SuperComputing 2025 in St. Louis, Missouri.

November 13, 2025
Moreh demonstrated that DeepSeek-R1 inference can be executed at a decoding throughput of >21,000 tokens/sec by implementing EP on the ROCm software stack.
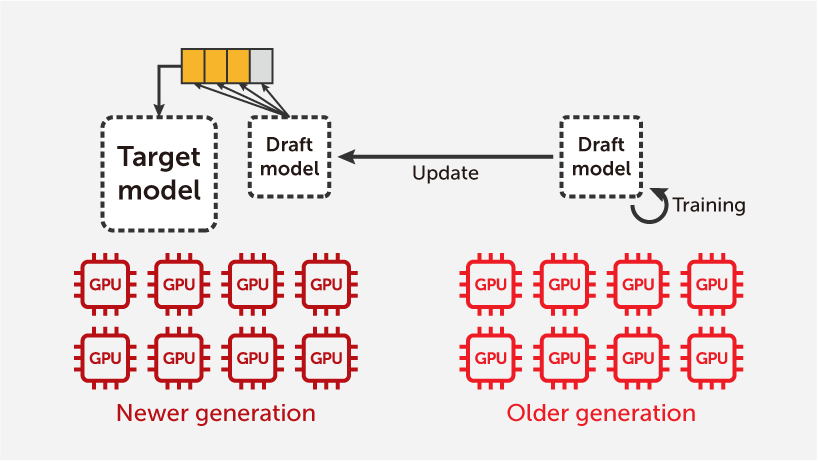
November 10, 2025
TIDE provides a method to optimize inference computation on newer GPUs by utilizing older or idle GPUs for runtime draft model training, resulting in better overall cost-performance at the system level.

November 7, 2025
EE Times — Cost-efficient AI at scale is a software problem, given that all Nvidia competitors are lagging behind on software development. Not only that, but software will also become even more critical as heterogeneity in the data center becomes commonplace.
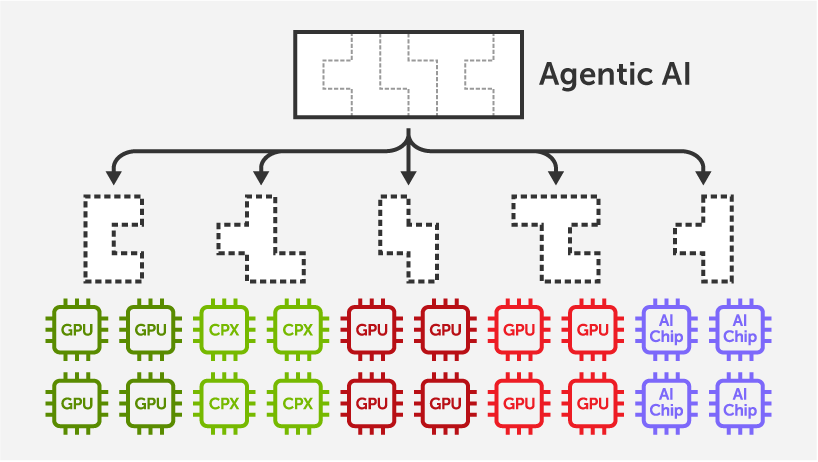
September 23, 2025
MoAI Inference Framework supports automatic and efficient distributed inference on heterogeneous accelerators such as AMD MI300X + MI308X and NVIDIA Rubin CPX + GPU.

September 11, 2025
Introducing distributed inference systems on AMD with greater efficiency than NVIDIA, and unveiling collaborations with Tenstorrent and SGLang.

August 30, 2025
Moreh vLLM achieves 1.68x higher output TPS, 2.02x lower TTFT, and 1.59x lower TPOT compared to the original vLLM for Meta's Llama 3.3 70B model.

August 29, 2025
Moreh vLLM achieves 1.68x higher output TPS, 1.75x lower TTFT, and 1.70x lower TPOT compared to the original vLLM for the DeepSeek V3/R1 671B model.

Moreh, Inc.
© 2026 Moreh, Inc. All right reserved.