Technical Report
HetCCL: Tăng tốc huấn luyện LLM với GPU không đồng nhất
January 30, 2026
Authors: Heehoon Kim, Jaehwan Lee (SNU), Taejeoung Kim (Samsung Research), Jongwon Park (SNU), Jinpyo Kim (SNU), Pyongwon Suh (Samsung Research), Ryan H. Choi (Samsung Research), Sangwoo Lee (Samsung Research), and Jaejin Lee
Tài liệu này được dịch tự động bằng AI. Nội dung có thể chưa chính xác, vui lòng tham khảo bản gốc tiếng Anh nếu cần. Xem bản gốc tiếng Anh
Tóm tắt
Sự phát triển nhanh chóng của các mô hình ngôn ngữ lớn đang thúc đẩy các tổ chức mở rộng cụm GPU của họ, thường sử dụng GPU từ nhiều nhà cung cấp khác nhau. Tuy nhiên, các framework học sâu hiện tại không hỗ trợ giao tiếp tập thể giữa các GPU không đồng nhất, dẫn đến sự kém hiệu quả và chi phí cao hơn. Chúng tôi giới thiệu HetCCL, một thư viện giao tiếp tập thể hợp nhất các backend theo nhà cung cấp và cho phép giao tiếp dựa trên RDMA giữa các GPU mà không cần sửa đổi driver. HetCCL giới thiệu hai cơ chế mới cho phép giao tiếp xuyên nhà cung cấp trong khi tận dụng các thư viện tối ưu hóa của nhà cung cấp, NVIDIA NCCL và AMD RCCL. Các đánh giá trên cụm GPU đa nhà cung cấp cho thấy HetCCL đạt hiệu suất tương đương NCCL và RCCL trong các thiết lập đồng nhất, đồng thời có khả năng mở rộng độc nhất trong môi trường không đồng nhất, cho phép huấn luyện thực tế, hiệu suất cao với cả GPU NVIDIA và AMD mà không cần thay đổi các ứng dụng học sâu hiện có.
1. Giới thiệu
Sự xuất hiện gần đây của các mô hình học sâu (DL) quy mô hàng nghìn tỷ tham số (Fedus et al., 2022; Achiam et al., 2023; Du et al., 2022) đã mở ra các giải pháp cho những bài toán trước đây không thể giải quyết được. Động lực chính đằng sau sự tiến bộ này là khả năng tính toán cao của các hệ thống cụm không đồng nhất được trang bị các bộ tăng tốc phần cứng đa dạng (ví dụ: GPU, NPU và FPGA), giúp việc huấn luyện và suy luận trên các mô hình khổng lồ trở nên khả thi. Trong số các hệ thống này, các nền tảng dựa trên GPU đóng vai trò chủ đạo trong DL, với GPU NVIDIA hoặc AMD là tiêu chuẩn thực tế (Otterness and Anderson, 2020; Lehdonvirta et al., 2025).
Để cho phép huấn luyện và suy luận hiệu quả các mô hình DL trên nhiều GPU, nhiều kỹ thuật song song hóa đã được phát triển. Các phương pháp tiêu biểu nhất là song song dữ liệu (Rajbhandari et al., 2020) và song song mô hình, bao gồm song song tensor, song song pipeline và song song chuyên gia (Shoeybi et al., 2019; Huang et al., 2019; Shazeer et al., 2017). Mặc dù các kỹ thuật này khác nhau về cách phân phối tính toán và dữ liệu trên các GPU, các hệ thống huấn luyện quy mô lớn hiện đại dựa vào song song hóa để cải thiện hiệu suất sử dụng phần cứng, khiến việc phối hợp hiệu quả giữa các thiết bị ngày càng quan trọng (Narayanan et al., 2021; Singh et al., 2023).
Trong huấn luyện hoặc suy luận song song đa GPU, giao tiếp giữa các GPU rất quan trọng để chia sẻ kết quả tính toán và đồng bộ hóa trạng thái mô hình. Các thao tác giao tiếp tập thể như All-Reduce, All-Gather và Reduce-Scatter thường được sử dụng cho mục đích này. Do đó, hầu hết các nhà cung cấp bộ tăng tốc đều cung cấp các thư viện giao tiếp tập thể (CCL) được tối ưu hóa cho phần cứng của họ. Ví dụ bao gồm NVIDIA NCCL (NVIDIA, 2025b), AMD RCCL (AMD, 2025c) và Intel oneCCL (Intel, 2025).
Huấn luyện các mô hình quy mô lớn thường yêu cầu các cụm dựa trên GPU khổng lồ. Trong thực tế, hầu hết các tổ chức mở rộng cụm của họ bằng cách mua hệ thống GPU theo từng giai đoạn (Park et al., 2020; Ding et al., 2021). Phương pháp mua sắm tăng dần này cho phép tiếp tục sử dụng các tài nguyên hiện có trong khi tích hợp phần cứng mới. Kết quả là, cơ sở hạ tầng trở nên không đồng nhất, bao gồm nhiều loại GPU khác nhau, đôi khi thậm chí từ các nhà cung cấp khác nhau.
Mặc dù GPU từ các nhà cung cấp khác nhau chia sẻ triết lý thiết kế và kiến trúc tương tự, chúng yêu cầu các framework và chuỗi công cụ riêng biệt, khiến việc phát triển phần mềm xuyên nhà cung cấp trở nên thách thức. Nhờ nỗ lực liên tục của cộng đồng, các framework DL đầy đủ tính năng hiện đã có sẵn cho GPU của mỗi nhà cung cấp. Ví dụ, PyTorch (Paszke et al., 2019) có thể được cấu hình để hỗ trợ GPU NVIDIA hoặc AMD. Tuy nhiên, huấn luyện song song trên GPU từ các nhà cung cấp khác nhau vẫn không khả thi do sự không tương thích của các backend giao tiếp. Các framework DL phụ thuộc vào các thư viện của nhà cung cấp cụ thể, như NCCL cho GPU NVIDIA và RCCL cho GPU AMD, và chúng không thể tương tác với nhau.
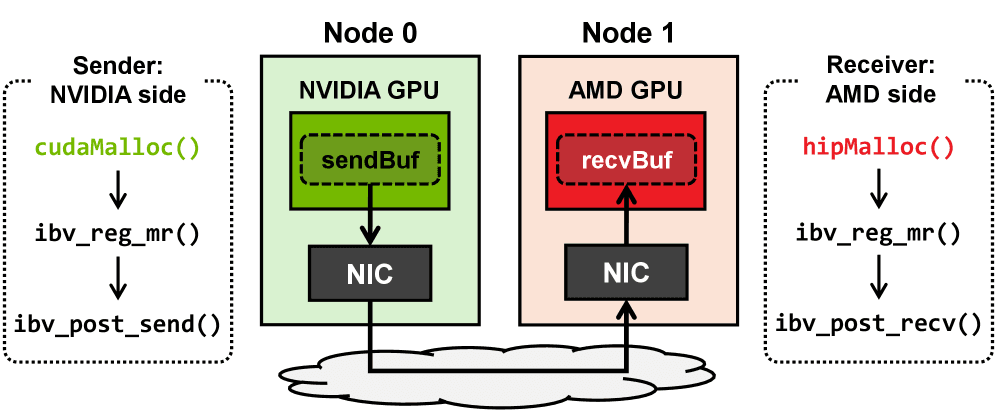
Khi khối lượng công việc DL mở rộng đến quy mô lớn hơn, khả năng đạt được giao tiếp nhanh và đáng tin cậy giữa các GPU không đồng nhất đang trở thành yếu tố quan trọng để xây dựng cơ sở hạ tầng AI có khả năng mở rộng và tiết kiệm chi phí. Nghiên cứu về giao tiếp như vậy, đặc biệt giữa GPU NVIDIA và AMD, không chỉ kịp thời mà còn thiết yếu cho sự phát triển của thế hệ tiếp theo các hệ thống ML phân tán. Với mục đích này, bài báo này giới thiệu HetCCL, một CCL hỗ trợ GPU từ nhiều nhà cung cấp. Theo hiểu biết tốt nhất của chúng tôi, HetCCL là công trình đầu tiên cho phép sử dụng minh bạch tất cả GPU đa nhà cung cấp trong một cụm không đồng nhất. Không cần sửa đổi mã nguồn ở bất kỳ cấp độ nào, bao gồm driver, runtime, compiler và ứng dụng. Đặc biệt, nó hỗ trợ GPU NVIDIA và AMD, hai nhà cung cấp hàng đầu theo thị phần, cùng nhau thống trị thị trường bộ tăng tốc (lần lượt khoảng 88% và 12%) (Lehdonvirta et al., 2025). Bằng cách thay thế các backend giao tiếp gốc (tức là NCCL và RCCL) bằng HetCCL, mã huấn luyện song song hiện có được viết trong các framework DL (ví dụ: PyTorch) có thể sử dụng GPU của cả hai nhà cung cấp mà không cần sửa đổi thêm.
Các đóng góp chính được tóm tắt như sau:
- Chúng tôi đề xuất HetCCL, CCL xuyên nhà cung cấp đầu tiên cho phép huấn luyện và suy luận mô hình DL trên các cụm không đồng nhất với cả GPU NVIDIA và AMD.
- Chúng tôi trình bày phương pháp giao tiếp point-to-point trực tiếp (tức là RDMA) giữa các GPU của các nhà cung cấp khác nhau.
- Chúng tôi mô tả thiết kế và triển khai các thao tác giao tiếp tập thể GPU không đồng nhất, tập trung vào các thách thức như trừu tượng hóa các API dành riêng cho nền tảng và tích hợp các thao tác tối ưu hóa của nhà cung cấp vào một framework thống nhất.
- Chúng tôi đánh giá hiệu suất huấn luyện các mô hình ngôn ngữ lớn trong cụm GPU đa nhà cung cấp và chứng minh rằng nó nhanh hơn nhiều so với các thiết lập đồng nhất mà không có bất kỳ hiệu ứng tụt hậu hay suy giảm độ chính xác mô hình nào.
Chúng tôi thảo luận về các hạn chế của công trình này và phác thảo các hướng nghiên cứu tương lai trong Phụ lục A.
Vui lòng đọc toàn bộ bài báo trên arXiv.