Technical Report
HetCCL:利用异构GPU加速LLM训练
January 30, 2026
Authors: Heehoon Kim, Jaehwan Lee (SNU), Taejeoung Kim (Samsung Research), Jongwon Park (SNU), Jinpyo Kim (SNU), Pyongwon Suh (Samsung Research), Ryan H. Choi (Samsung Research), Sangwoo Lee (Samsung Research), and Jaejin Lee
本文档由AI自动翻译。内容可能存在不准确之处,如有需要请参阅英文原文。 查看英文原文
摘要
大语言模型的快速增长促使各组织扩展其GPU集群,通常需要使用来自多个供应商的GPU。然而,当前的深度学习框架不支持异构GPU之间的集合通信,导致效率低下和成本增加。我们提出了HetCCL,一个统一供应商特定后端并在无需修改驱动程序的情况下实现GPU间基于RDMA通信的集合通信库。HetCCL引入了两种新机制,在利用优化的供应商库NVIDIA NCCL和AMD RCCL的同时实现跨供应商通信。在多供应商GPU集群上的评估表明,HetCCL在同构设置中可匹配NCCL和RCCL的性能,同时在异构环境中具有独特的扩展能力,无需更改现有深度学习应用程序即可实现使用NVIDIA和AMD GPU的实用高性能训练。
1. 引言
近年来万亿级深度学习(DL)模型(Fedus et al., 2022; Achiam et al., 2023; Du et al., 2022)的出现,使得解决以前难以处理的问题成为可能。这一进步背后的关键推动力是配备各种硬件加速器(如GPU、NPU和FPGA)的异构集群系统的高计算能力,使训练和推理如此大规模的模型成为可能。在这些系统中,基于GPU的平台在DL领域占据主导地位,NVIDIA或AMD GPU已成为事实上的标准(Otterness and Anderson, 2020; Lehdonvirta et al., 2025)。
为了在多个GPU上实现DL模型的高效训练和推理,已开发了多种并行化技术。最具代表性的方法是数据并行(Rajbhandari et al., 2020)和模型并行,包括张量并行、流水线并行和专家并行(Shoeybi et al., 2019; Huang et al., 2019; Shazeer et al., 2017)。虽然这些技术在GPU间分配计算和数据的方式各不相同,但现代大规模训练系统依赖并行化来提高硬件利用率,使设备间的高效协调变得越来越重要(Narayanan et al., 2021; Singh et al., 2023)。
在多GPU并行训练或推理中,GPU间通信对于共享计算结果和同步模型状态至关重要。集合通信操作(如All-Reduce、All-Gather和Reduce-Scatter)通常用于此目的。因此,大多数加速器供应商提供针对其硬件优化的集合通信库(CCL)。例如NVIDIA NCCL(NVIDIA, 2025b)、AMD RCCL(AMD, 2025c)和Intel oneCCL(Intel, 2025)。
训练大规模模型通常需要大规模的基于GPU的集群。在实践中,大多数组织通过逐步采购GPU系统来扩展其集群(Park et al., 2020; Ding et al., 2021)。这种增量采购方式允许在集成新硬件的同时继续使用现有资源。因此,基础设施变得异构化,包含各种类型的GPU,有时甚至来自不同的供应商。
虽然不同供应商的GPU共享类似的设计理念和架构,但它们需要不同的框架和工具链,使得跨供应商软件开发具有挑战性。得益于持续的社区努力,目前每个供应商的GPU都有功能完整的DL框架可用。例如,PyTorch(Paszke et al., 2019)可以配置为支持NVIDIA或AMD GPU。然而,由于通信后端的不兼容性,跨不同供应商GPU的并行训练仍然不可行。DL框架依赖于供应商特定的库,如用于NVIDIA GPU的NCCL和用于AMD GPU的RCCL,这些库彼此不可互操作。
随着DL工作负载扩展到更大规模,实现异构GPU之间快速可靠通信的能力正成为构建可扩展且经济高效的AI基础设施的关键因素。研究这种通信,特别是NVIDIA和AMD GPU之间的通信,不仅适时而且对下一代分布式ML系统的发展至关重要。为此,本文提出了HetCCL,一个支持多供应商GPU的CCL。据我们所知,HetCCL是首个在异构集群中实现所有多供应商GPU透明利用的工作。在驱动程序、运行时、编译器和应用程序等任何层面都无需修改源代码。特别是,它支持按市场份额排名前两位的供应商NVIDIA和AMD的GPU,这两个供应商共同主导着加速器市场(分别约占88%和12%)(Lehdonvirta et al., 2025)。通过将原始通信后端(即NCCL和RCCL)替换为HetCCL,使用DL框架(如PyTorch)编写的现有并行训练代码可以无需进一步修改即可使用两个供应商的GPU。
主要贡献总结如下:
- 我们提出了HetCCL,首个跨供应商CCL,能够在同时配备NVIDIA和AMD GPU的异构集群上进行DL模型训练和推理。
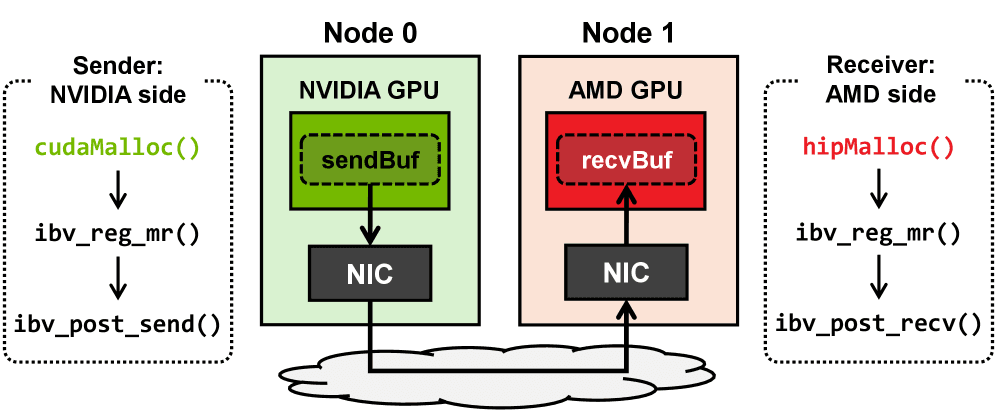
- 我们提出了一种不同供应商GPU之间直接point-to-point通信(即RDMA)的方法。
- 我们描述了异构GPU集合通信操作的设计和实现,重点讨论了平台特定API抽象化以及将供应商优化操作集成到统一框架中的挑战。
- 我们评估了多供应商GPU集群中大语言模型的训练性能,并证明其比同构设置快得多,且没有任何落后效应或模型精度下降。
我们在附录A中讨论了本工作的局限性并概述了未来研究方向。
请在 arXiv上阅读完整论文。