Technical Report
HetCCL: 이기종 GPU를 활용한 LLM 학습 가속화
January 30, 2026
Authors: Heehoon Kim, Jaehwan Lee (SNU), Taejeoung Kim (Samsung Research), Jongwon Park (SNU), Jinpyo Kim (SNU), Pyongwon Suh (Samsung Research), Ryan H. Choi (Samsung Research), Sangwoo Lee (Samsung Research), and Jaejin Lee
이 문서는 AI를 통해 자동 번역되었습니다. 어색하거나 부정확한 내용이 있을 수 있으니, 필요한 경우 영어 원문을 참고해 주세요. 영어 원문 보기
초록
대규모 언어 모델의 급속한 성장으로 인해 조직들은 GPU 클러스터를 확장하고 있으며, 종종 여러 벤더의 GPU를 함께 사용하게 됩니다. 그러나 현재의 딥러닝 프레임워크는 이기종 GPU 간의 집합 통신을 지원하지 않아 비효율성과 비용 증가를 초래합니다. 본 논문에서는 벤더별 백엔드를 통합하고 드라이버 수정 없이 GPU 간 RDMA 기반 통신을 가능하게 하는 집합 통신 라이브러리인 HetCCL을 소개합니다. HetCCL은 최적화된 벤더 라이브러리인 NVIDIA NCCL과 AMD RCCL을 활용하면서 크로스 벤더 통신을 가능하게 하는 두 가지 새로운 메커니즘을 도입합니다. 다중 벤더 GPU 클러스터에서의 평가 결과, HetCCL은 동종 환경에서 NCCL 및 RCCL 성능에 필적하면서도 이기종 환경에서는 고유하게 확장이 가능하여 기존 딥러닝 애플리케이션을 변경하지 않고도 NVIDIA와 AMD GPU를 모두 활용한 실용적이고 고성능인 학습을 가능하게 합니다.
1. 서론
최근 조 단위 규모의 딥러닝(DL) 모델(Fedus et al., 2022; Achiam et al., 2023; Du et al., 2022)의 등장으로 이전에는 해결 불가능했던 문제들에 대한 솔루션이 가능해졌습니다. 이러한 발전의 핵심 동력은 다양한 하드웨어 가속기(예: GPU, NPU, FPGA)를 갖춘 이기종 클러스터 시스템의 높은 연산 능력으로, 이를 통해 대규모 모델의 학습 및 추론이 가능해졌습니다. 이러한 시스템 중에서 GPU 기반 플랫폼이 DL에서 지배적인 역할을 하며, NVIDIA 또는 AMD GPU가 사실상의 표준으로 사용되고 있습니다(Otterness and Anderson, 2020; Lehdonvirta et al., 2025).
여러 GPU에 걸친 효율적인 DL 모델 학습 및 추론을 위해 다양한 병렬화 기법이 개발되었습니다. 가장 대표적인 접근법은 데이터 병렬화(Rajbhandari et al., 2020)와 텐서, 파이프라인, 전문가 병렬화를 포함하는 모델 병렬화(Shoeybi et al., 2019; Huang et al., 2019; Shazeer et al., 2017)입니다. 이러한 기법들은 연산과 데이터를 GPU에 분배하는 방식이 다르지만, 현대의 대규모 학습 시스템은 하드웨어 활용도를 향상시키기 위해 병렬화에 의존하고 있으며, 이로 인해 디바이스 간의 효율적인 조정이 점점 더 중요해지고 있습니다(Narayanan et al., 2021; Singh et al., 2023).
다중 GPU 병렬 학습 또는 추론에서 GPU 간 통신은 연산 결과의 공유와 모델 상태의 동기화에 매우 중요합니다. All-Reduce, All-Gather, Reduce-Scatter 등의 집합 통신 연산이 이 목적으로 일반적으로 사용됩니다. 이에 따라 대부분의 가속기 벤더는 자사 하드웨어에 최적화된 집합 통신 라이브러리(CCL)를 제공합니다. 대표적인 예로 NVIDIA NCCL(NVIDIA, 2025b), AMD RCCL(AMD, 2025c), Intel oneCCL(Intel, 2025)이 있습니다.
대규모 모델 학습에는 일반적으로 대규모 GPU 기반 클러스터가 필요합니다. 실제로 대부분의 조직은 GPU 시스템을 점진적으로 구매하는 방식으로 클러스터를 확장합니다(Park et al., 2020; Ding et al., 2021). 이러한 점진적 조달 방식을 통해 기존 자원을 계속 활용하면서 새로운 하드웨어를 통합할 수 있습니다. 그 결과 인프라는 다양한 유형의 GPU를 포함하는 이기종 환경이 되며, 때로는 서로 다른 벤더의 GPU가 혼재하게 됩니다.
서로 다른 벤더의 GPU는 유사한 설계 철학과 아키텍처를 공유하지만, 별도의 프레임워크와 도구 체인이 필요하여 크로스 벤더 소프트웨어 개발이 어렵습니다. 지속적인 커뮤니티 노력 덕분에 각 벤더의 GPU에 대한 완전한 기능의 DL 프레임워크가 이제 사용 가능합니다. 예를 들어 PyTorch(Paszke et al., 2019)는 NVIDIA 또는 AMD GPU를 지원하도록 구성할 수 있습니다. 그러나 통신 백엔드의 비호환성으로 인해 서로 다른 벤더의 GPU 간 병렬 학습은 여전히 불가능합니다. DL 프레임워크는 NVIDIA GPU용 NCCL과 AMD GPU용 RCCL 같은 벤더별 라이브러리에 의존하며, 이들은 상호 운용되지 않습니다.
DL 워크로드가 더 큰 규모로 확장됨에 따라, 이기종 GPU 간의 빠르고 안정적인 통신 능력은 확장 가능하고 비용 효율적인 AI 인프라를 구축하는 데 핵심 요소가 되고 있습니다. 특히 NVIDIA와 AMD GPU 간의 이러한 통신을 연구하는 것은 시의적절할 뿐만 아니라 차세대 분산 ML 시스템의 발전에 필수적입니다. 이를 위해 본 논문은 여러 벤더의 GPU를 지원하는 CCL인 HetCCL을 제시합니다. 우리가 아는 한, HetCCL은 이기종 클러스터에서 모든 다중 벤더 GPU의 투명한 활용을 가능하게 한 최초의 연구입니다. 드라이버, 런타임, 컴파일러, 애플리케이션 등 어떤 수준에서도 소스 코드 수정이 필요하지 않습니다. 특히 시장 점유율 기준 상위 두 벤더인 NVIDIA와 AMD GPU를 지원하며, 이 두 벤더가 가속기 시장을 지배하고 있습니다(각각 약 88%와 12%)(Lehdonvirta et al., 2025). 기존의 통신 백엔드(즉, NCCL과 RCCL)를 HetCCL로 교체함으로써 DL 프레임워크(예: PyTorch)로 작성된 기존 병렬 학습 코드가 추가 수정 없이 양 벤더의 GPU를 사용할 수 있습니다.
주요 기여는 다음과 같이 요약됩니다:
- NVIDIA와 AMD GPU를 모두 갖춘 이기종 클러스터에서 DL 모델 학습 및 추론을 가능하게 하는 최초의 크로스 벤더 CCL인 HetCCL을 제안합니다.
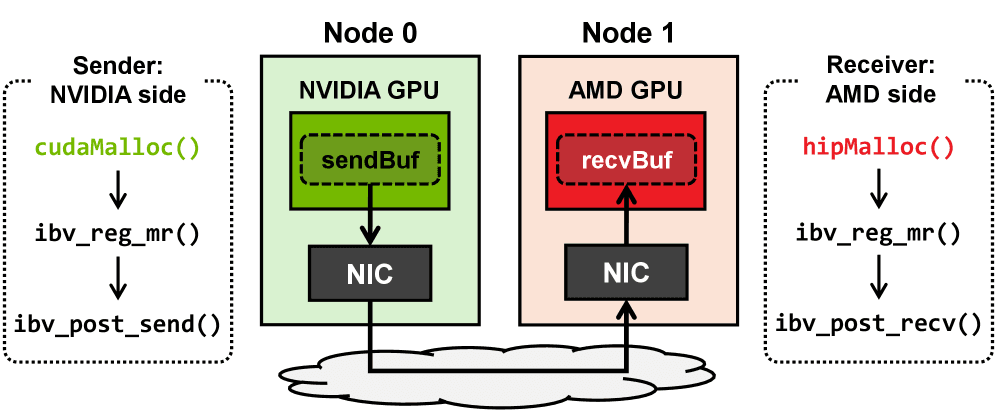
- 서로 다른 벤더의 GPU 간 직접적인 point-to-point 통신(즉, RDMA) 방법을 제시합니다.
- 플랫폼별 API 추상화 및 벤더 최적화 연산을 통합 프레임워크에 통합하는 과제를 중심으로 이기종 GPU 집합 통신 연산의 설계와 구현을 설명합니다.
- 다중 벤더 GPU 클러스터에서 대규모 언어 모델의 학습 성능을 평가하고, 낙오 효과나 모델 정확도 저하 없이 동종 환경보다 훨씬 빠른 성능을 달성함을 실증합니다.
본 연구의 한계와 향후 연구 방향은 부록 A에서 논의합니다.
전체 논문은 arXiv에서 읽으실 수 있습니다.