Technical Report
HetCCL:異種GPUによるLLMトレーニングの高速化
January 30, 2026
Authors: Heehoon Kim, Jaehwan Lee (SNU), Taejeoung Kim (Samsung Research), Jongwon Park (SNU), Jinpyo Kim (SNU), Pyongwon Suh (Samsung Research), Ryan H. Choi (Samsung Research), Sangwoo Lee (Samsung Research), and Jaejin Lee
この文書はAIによって自動翻訳されたものです。不自然な表現や不正確な内容が含まれる場合がありますので、必要に応じて英語の原文をご参照ください。 英語の原文を見る
概要
大規模言語モデルの急速な成長により、組織はGPUクラスターを拡張しており、複数のベンダーのGPUを使用するケースが増えています。しかし、現在のディープラーニングフレームワークは異種GPU間の集合通信をサポートしておらず、非効率性とコスト増加を招いています。本論文では、ベンダー固有のバックエンドを統合し、ドライバーの変更なしにGPU間のRDMAベースの通信を可能にする集合通信ライブラリであるHetCCLを紹介します。HetCCLは、最適化されたベンダーライブラリであるNVIDIA NCCLとAMD RCCLを活用しながら、クロスベンダー通信を可能にする2つの新しいメカニズムを導入しています。マルチベンダーGPUクラスターでの評価により、HetCCLは同種環境ではNCCLおよびRCCLの性能に匹敵し、異種環境では独自のスケーリングが可能であることが示され、既存のディープラーニングアプリケーションを変更することなくNVIDIAとAMD GPUの両方を使用した実用的で高性能なトレーニングが実現されます。
1. はじめに
近年の兆規模のディープラーニング(DL)モデル(Fedus et al., 2022; Achiam et al., 2023; Du et al., 2022)の登場により、以前は解決不可能だった問題への解決策が可能になりました。この進歩の主要な原動力は、さまざまなハードウェアアクセラレータ(例:GPU、NPU、FPGA)を備えた異種クラスターシステムの高い計算能力であり、このような大規模モデルのトレーニングと推論を実現可能にしています。これらのシステムの中で、GPUベースのプラットフォームがDLにおいて支配的な役割を果たしており、NVIDIAまたはAMD GPUが事実上の標準として使用されています(Otterness and Anderson, 2020; Lehdonvirta et al., 2025)。
複数のGPUにわたるDLモデルの効率的なトレーニングと推論を実現するために、さまざまな並列化技術が開発されています。最も代表的なアプローチは、データ並列化(Rajbhandari et al., 2020)と、テンソル並列、パイプライン並列、エキスパート並列を含むモデル並列化(Shoeybi et al., 2019; Huang et al., 2019; Shazeer et al., 2017)です。これらの技術は計算とデータをGPU間でどのように分配するかが異なりますが、現代の大規模トレーニングシステムはハードウェア利用率を向上させるために並列化に依存しており、デバイス間の効率的な調整がますます重要になっています(Narayanan et al., 2021; Singh et al., 2023)。
マルチGPUの並列トレーニングまたは推論において、GPU間通信は計算結果の共有とモデル状態の同期に不可欠です。All-Reduce、All-Gather、Reduce-Scatterなどの集合通信操作がこの目的で一般的に使用されています。そのため、ほとんどのアクセラレータベンダーは、自社ハードウェアに最適化された集合通信ライブラリ(CCL)を提供しています。例としては、NVIDIA NCCL(NVIDIA, 2025b)、AMD RCCL(AMD, 2025c)、Intel oneCCL(Intel, 2025)があります。
大規模モデルのトレーニングには通常、大規模なGPUベースのクラスターが必要です。実際には、ほとんどの組織はGPUシステムを段階的に購入してクラスターを拡張しています(Park et al., 2020; Ding et al., 2021)。この段階的な調達アプローチにより、既存のリソースを継続的に使用しながら新しいハードウェアを統合できます。その結果、インフラストラクチャは異種化し、さまざまなタイプのGPUを含むようになり、時には異なるベンダーのGPUが混在することもあります。
異なるベンダーのGPUは類似の設計思想とアーキテクチャを共有していますが、異なるフレームワークとツールチェーンが必要であり、クロスベンダーのソフトウェア開発を困難にしています。継続的なコミュニティの取り組みにより、各ベンダーのGPU向けのフル機能のDLフレームワークが利用可能になっています。例えば、PyTorch(Paszke et al., 2019)はNVIDIAまたはAMD GPUをサポートするように構成できます。しかし、通信バックエンドの非互換性のため、異なるベンダーのGPU間での並列トレーニングは依然として実現不可能です。DLフレームワークはNVIDIA GPU用のNCCLやAMD GPU用のRCCLなどのベンダー固有のライブラリに依存しており、これらは相互運用できません。
DLワークロードがより大規模にスケールするにつれ、異種GPU間の高速で信頼性の高い通信能力は、スケーラブルでコスト効率の高いAIインフラストラクチャを構築するための重要な要素となっています。このような通信、特にNVIDIAとAMD GPU間の通信を研究することは、時宜を得ているだけでなく、次世代の分散MLシステムの発展に不可欠です。この目的のため、本論文では複数ベンダーのGPUをサポートするCCLであるHetCCLを提示します。我々の知る限り、HetCCLは異種クラスターにおけるすべてのマルチベンダーGPUの透過的な利用を可能にした初めての研究です。ドライバー、ランタイム、コンパイラ、アプリケーションを含むいかなるレベルでもソースコードの変更は不要です。特に、市場シェアで上位2社であるNVIDIAとAMD GPUをサポートしており、この2社がアクセラレータ市場を支配しています(それぞれ約88%と12%)(Lehdonvirta et al., 2025)。元の通信バックエンド(すなわちNCCLとRCCL)をHetCCLに置き換えることで、DLフレームワーク(例:PyTorch)で記述された既存の並列トレーニングコードが、さらなる変更なしに両ベンダーのGPUを使用できます。
主な貢献は以下のとおりです:
- NVIDIAとAMD GPUの両方を備えた異種クラスターでのDLモデルのトレーニングと推論を可能にする、初のクロスベンダーCCLであるHetCCLを提案します。
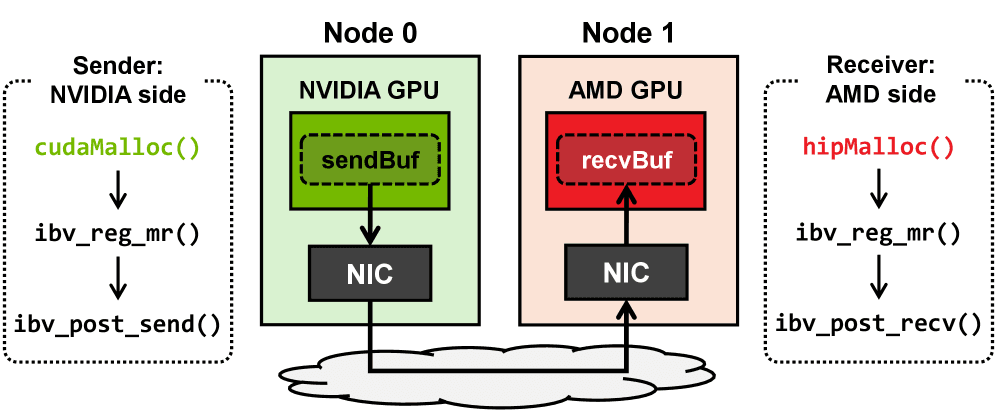
- 異なるベンダーのGPU間の直接的なpoint-to-point通信(すなわちRDMA)の方法を提示します。
- プラットフォーム固有のAPIの抽象化やベンダー最適化された操作の統合フレームワークへの統合といった課題に重点を置き、異種GPU集合通信操作の設計と実装を説明します。
- マルチベンダーGPUクラスターにおける大規模言語モデルのトレーニング性能を評価し、ストラグラー効果やモデル精度の低下なしに同種セットアップよりもはるかに高速であることを実証します。
本研究の限界と今後の研究方向については付録Aで議論します。
論文の全文は arXivでお読みいただけます。